데이터 분석을 할 때 결측치(NaN)는 흔히 발생하는 문제 중 하나입니다. 결측치는 잘못된 분석 결과를 초래할 수 있기 때문에, 이를 적절하게 처리하는 것이 중요합니다. Pandas는 다양한 결측치 처리 기능을 제공하여 데이터를 정제하고 분석의 정확성을 높일 수 있습니다. 이번 포스팅에서는 Pandas에서 결측치를 처리하는 여러 방법을 예시 코드와 함께 소개하겠습니다.
1. 결측치 확인하기
먼저, 결측치를 처리하기 전에 데이터셋에서 결측치가 있는지 확인해야 합니다. isnull() 메서드를 사용하여 데이터프레임 내의 결측치를 확인할 수 있습니다.
import pandas as pd# 예제 데이터 생성 = {'이름' : ['Alice' , 'Bob' , 'Charlie' , None ],'나이' : [24 , None , 22 , 25 ],'점수' : [85 , 90 , None , 88 ]= pd.DataFrame(data)# 결측치 확인
0
False
False
False
1
False
True
False
2
False
False
True
3
True
False
False
위 코드에서는 각 값이 결측치인지 여부를 True/False로 표시합니다. 결측치의 개수를 확인하고 싶다면 sum() 메서드를 사용합니다.
# 컬럼별 결측치 개수 확인 print (df.isnull().sum ())
이름 1
나이 1
점수 1
dtype: int64
2. 결측치 제거하기
dropna() 메서드결측치를 포함한 행 또는 열을 제거할 때 사용합니다.
axis=0 (기본값): 결측치가 있는 행을 제거합니다.axis=1: 결측치가 있는 열을 제거합니다.how='all': 모든 값이 결측치일 때만 제거합니다.
# 결측치가 있는 행 제거 = df.dropna()print (df_dropna_rows)
이름 나이 점수
0 Alice 24.0 85.0
# 결측치가 있는 열 제거 = df.dropna(axis= 1 )print (df_dropna_cols)
Empty DataFrame
Columns: []
Index: [0, 1, 2, 3]
3. 결측치 채우기
fillna() 메서드결측치를 특정 값으로 채우고자 할 때 사용합니다. 다양한 옵션을 사용하여 결측치를 채울 수 있습니다.
1. 단일 값으로 채우기
# 결측치를 0으로 채우기 = df.fillna(0 )print (df_fillna_0)
이름 나이 점수
0 Alice 24.0 85.0
1 Bob 0.0 90.0
2 Charlie 22.0 0.0
3 0 25.0 88.0
2. 컬럼별 다른 값으로 채우기
각 컬럼마다 다른 값을 사용하여 결측치를 채울 수 있습니다.
# 컬럼별로 다른 값으로 채우기 = df.fillna({'이름' : 'Unknown' , '나이' : df['나이' ].mean(), '점수' : 50 })print (df_fillna_custom)
이름 나이 점수
0 Alice 24.000000 85.0
1 Bob 23.666667 90.0
2 Charlie 22.000000 50.0
3 Unknown 25.000000 88.0
3. 이전/다음 값으로 채우기 (method 옵션)
이전 값이나 다음 값으로 결측치를 채울 수 있습니다.
# 앞의 값으로 채우기 (forward fill) = df.ffill()print (df_fillna_ffill)
이름 나이 점수
0 Alice 24.0 85.0
1 Bob 24.0 90.0
2 Charlie 22.0 90.0
3 Charlie 25.0 88.0
# 뒤의 값으로 채우기 (backward fill) = df.bfill()print (df_fillna_bfill)
이름 나이 점수
0 Alice 24.0 85.0
1 Bob 22.0 90.0
2 Charlie 22.0 88.0
3 NaN 25.0 88.0
4. 결측치 대체하기
replace() 메서드특정 값을 다른 값으로 대체할 때 사용합니다. 결측치뿐만 아니라 다른 값도 대체할 수 있습니다.
# 'Bob'을 'Robert'으로 변경 = df.replace('Bob' , 'Robert' )print (df_replace)
이름 나이 점수
0 Alice 24.0 85.0
1 Robert NaN 90.0
2 Charlie 22.0 NaN
3 NaN 25.0 88.0
결측치를 특정 값으로 대체할 수도 있습니다.
# NaN을 0으로 대체 = df.replace({None : 'Unknown' })print (df_replace_nan)
이름 나이 점수
0 Alice 24.0 85.0
1 Bob NaN 90.0
2 Charlie 22.0 NaN
3 Unknown 25.0 88.0
5. 결측치 보간하기
interpolate() 메서드숫자 데이터를 가진 컬럼에서 결측치를 선형 보간법 등으로 채울 수 있습니다.
# 선형 보간법을 사용하여 결측치 채우기 = df.select_dtypes(include= 'number' ).interpolate()print (df_interpolate)
나이 점수
0 24.0 85.0
1 23.0 90.0
2 22.0 89.0
3 25.0 88.0
보간 방법은 ‘linear’ 이외에도 다양한 옵션이 있습니다. pandas의 interpolate() 함수는 결측값(NaN)을 보간할 때 사용할 수 있는 다양한 보간 방법을 제공합니다. 주요 보간 방법은 다음과 같습니다.
method 파라미터 옵션interpolate() 함수의 method 파라미터를 사용하여 다양한 보간 방법을 선택할 수 있습니다. 기본적인 보간 방법은 다음과 같습니다:
'linear''time'index 또는 column이 datetime 타입이어야 합니다.'index'index를 기준으로 선형 보간을 수행합니다.'pad' / 'ffill''backfill' / 'bfill''nearest''polynomial'order 파라미터로 다항식의 차수를 지정해야 합니다. 예를 들어, method='polynomial', order=2는 2차 다항식 보간입니다.
기타 파라미터
limitlimit_direction'forward', 'backward', 'both'로 보간의 방향을 지정합니다.limit_area'inside', 'outside'로 보간이 이루어지는 영역을 제한합니다.axis0은 행(row), 1은 열(column)을 의미합니다.
사용 예시
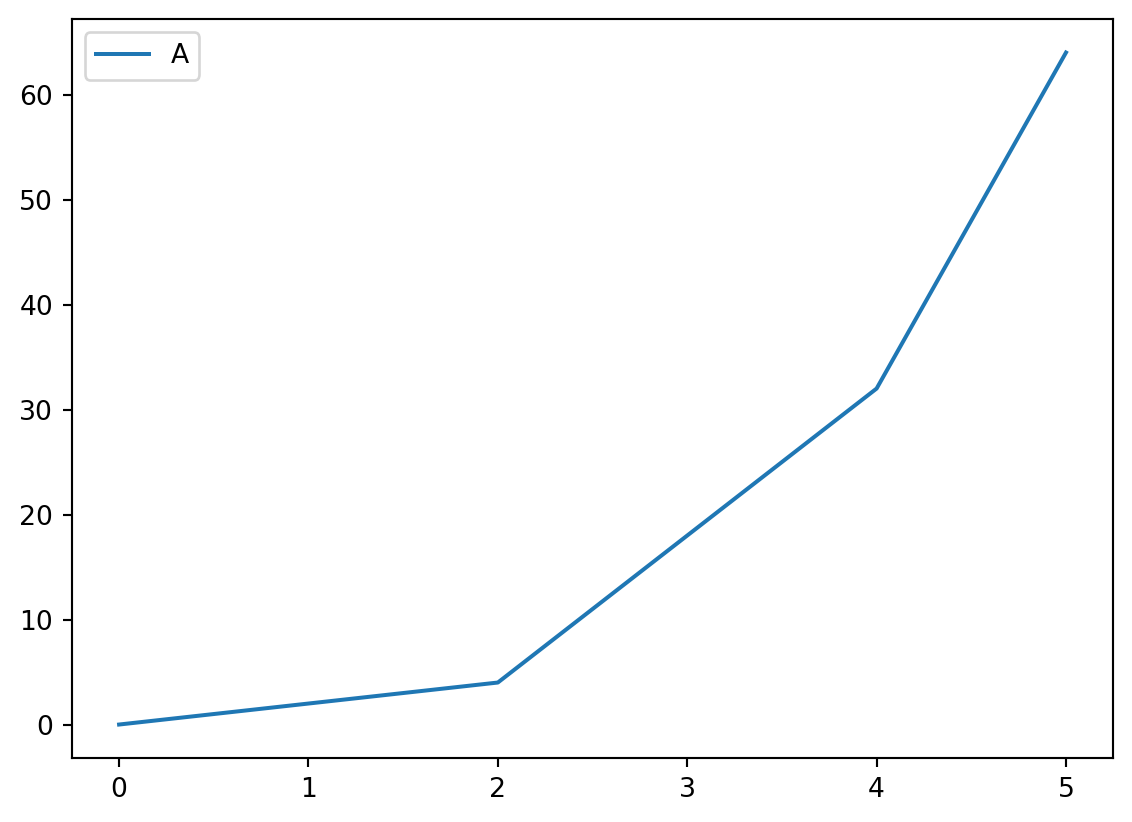
import pandas as pdimport numpy as np# 예제 데이터 생성 = {'A' : [0 , np.nan, 4 , np.nan, 32 , 64 ]}= pd.DataFrame(data)# 선형 보간 = df.interpolate(method= 'linear' )
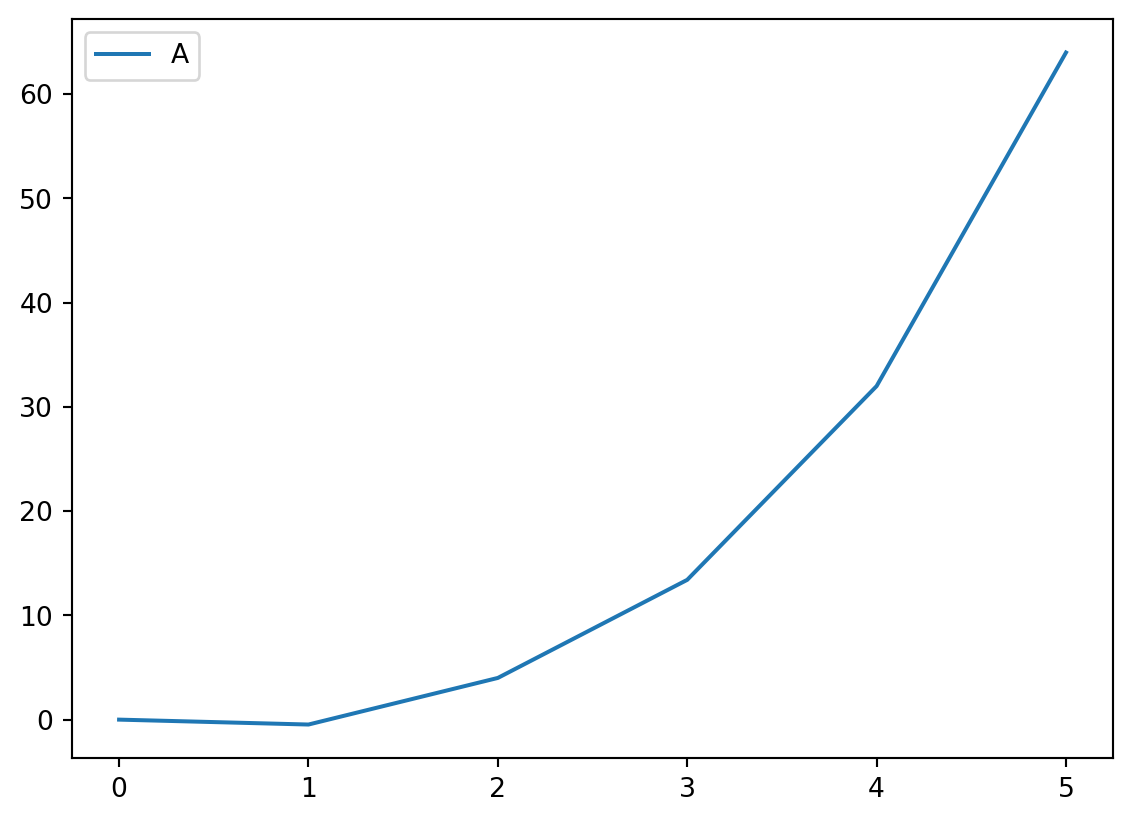
2차 다항식 보간은 아래와 같습니다.
# 2차 다항식 보간 = df.interpolate(method= 'polynomial' , order= 2 )
각 방법은 데이터의 특성에 따라 적합한 보간법을 선택해야 하며, 데이터의 패턴과 성격에 맞는 보간 방법을 사용하는 것이 중요합니다.
Date
Title
Author
Oct 3, 2024
Pandas에서 Column 추가 및 삭제하는 방법
gabriel yang
Oct 3, 2024
Pandas 데이터프레임 mongodb에 저장하기
gabriel yang
Sep 11, 2024
Pandas SQL 쿼리 이용하기
gabriel yang
Aug 29, 2024
Pandas에서 데이터 형식 변경하기
gabriel yang
Aug 29, 2024
Pandas에서 데이터를 정렬하는 방법
gabriel yang
Aug 29, 2024
Pandas에서 인덱싱 및 슬라이싱하는 방법
gabriel yang
Aug 27, 2024
Pandas SQL 데이터베이스 읽어오기
gabriel yang
Aug 26, 2024
Pandas groupby 사용방법
gabriel yang
Aug 26, 2024
Pandas에서 두 개의 데이터프레임을 연결하기
gabriel yang
Aug 24, 2024
Pandas에서 melt를 사용해야 하는 데이터 유형과 사용 방법
gabriel yang
Aug 24, 2024
Pandas에서 pivot_table 사용하기
gabriel yang
Aug 24, 2024
Pandas에서 reset_index를 사용해야 하는 이유
gabriel yang
Aug 22, 2024
Pandas Excel과 CSV 파일을 읽어오는 방법
gabriel yang
Aug 19, 2024
Pandas DataFrame의 컬럼 이름 변경하기
gabriel yang
Aug 17, 2024
Pandas SettingWithCopyWarning 문제 해결
gabriel yang
Nov 30, 2023
Dataframe을 Dict로 생성 및 변환
gabriel yang
Nov 29, 2023
python datetime 사용법 정리
gabriel yang
Sep 14, 2023
Pandas 중복 데이터 제거하기
gabriel yang
No matching items